Spark stateful streaming processing is stuck in StateStoreSave stage!
A stateful structured stream processing job is suddenly stuck at the 1st micro-batch job. Here are the notes about that issue, how to debug Spark stateful streaming job, and also how I fix it.
Stateful Structured Streaming Processing Job
1 | ## specify data source, read data from Azure Event Hub |
Spark SQL converts batch-like query to a series of incremental execution plans operating on new micro-batches of data.
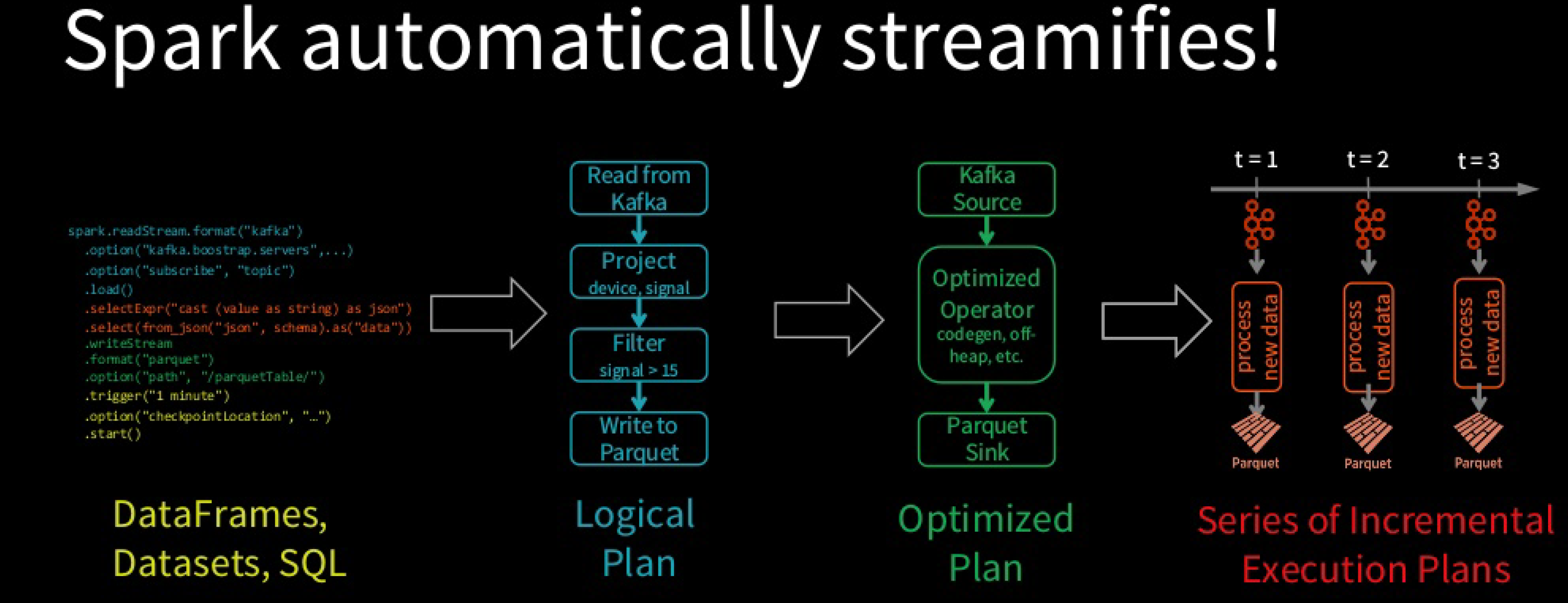
Environment
This Streaming job is running on Databricks clusters triggered by Azure Data Factory pipeline.
Data source is from Azure Event Hub, and this job store the aggregated output to Azure Blob Storage mounted on Databricks.
Databricks instance has Vnet injections and have NSG associated with the Vnet.
Databricks cluster version is 5.5 LTS which use Scala 2.11, Spark 2.4.3 and Python 3.
We also use PySpark 2.4.4 for this streaming job.
Issue Symptom
This streaming job is scheduled to run for 4 hours every time. When the current job stops, the next one will start to run. It means the max number of concurrency job is 1.
It was running well before. Suddenly, when a new streaming job starts, it seems to stuck at the 1st micro-batch like the following picture. You can see the job is stuck for batch=0 and it fails because of time out.
We have 3 regions and this issue happened to every region one by one in a week.
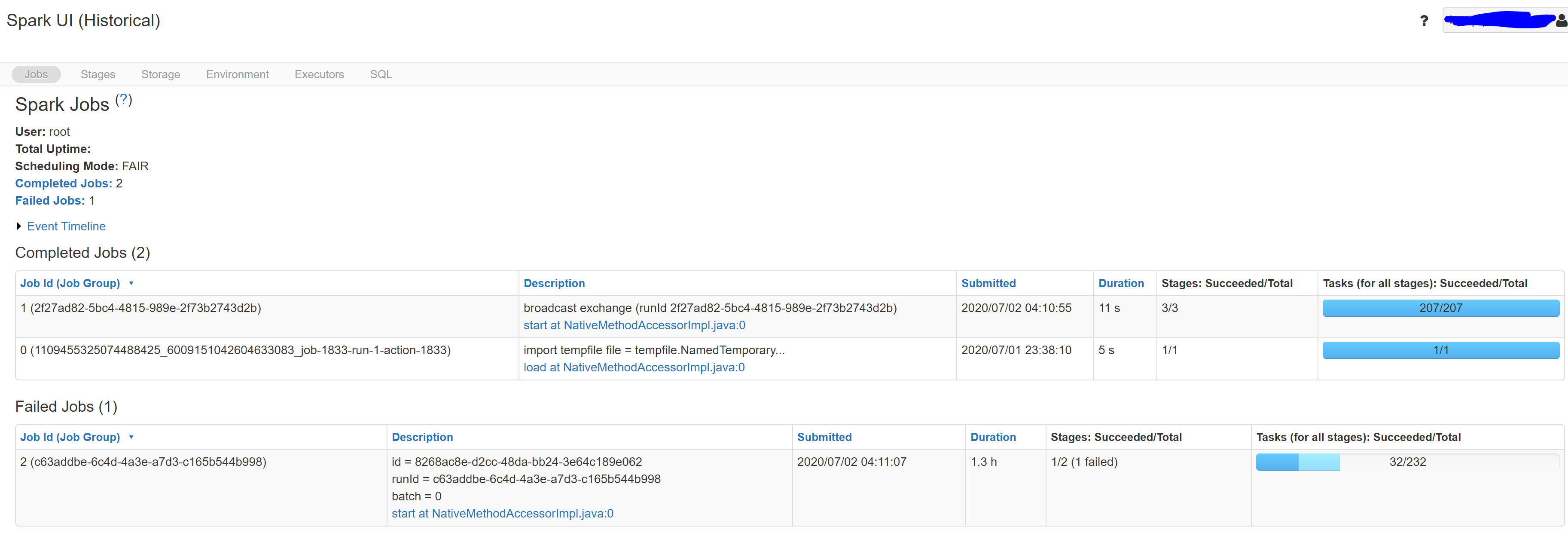
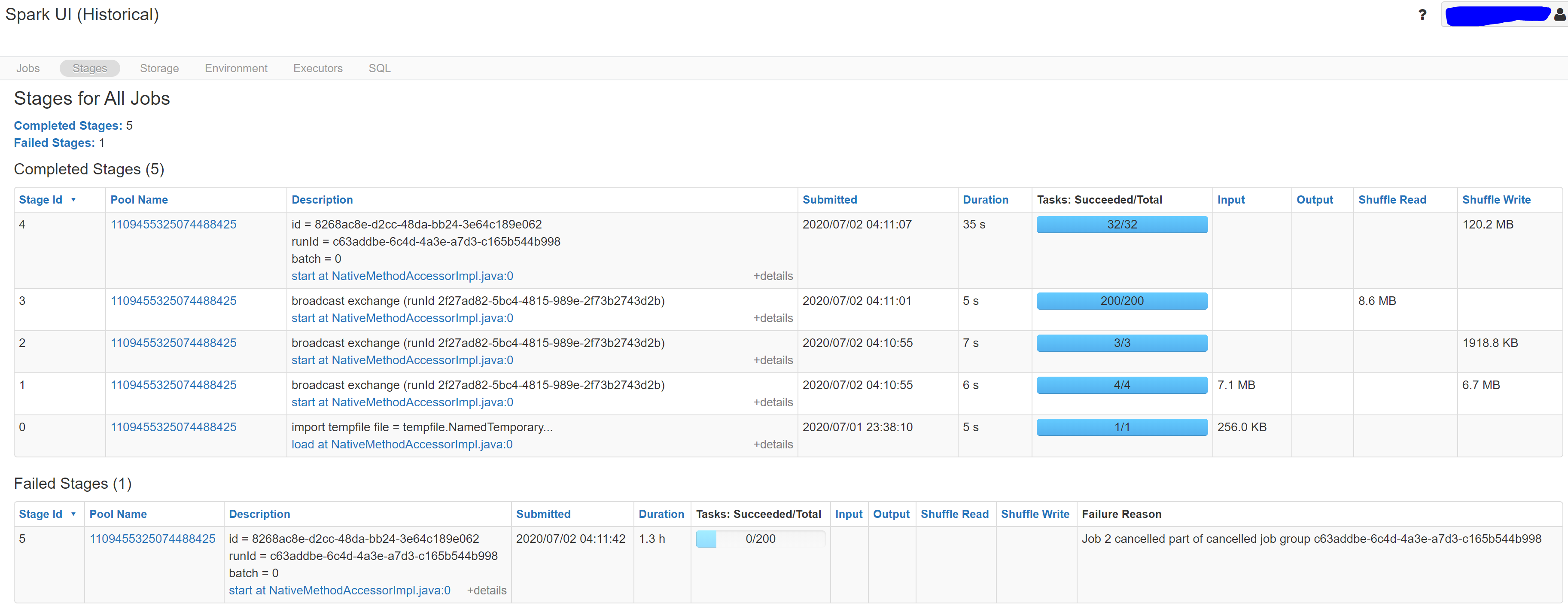
If you check the checkpoint folder:
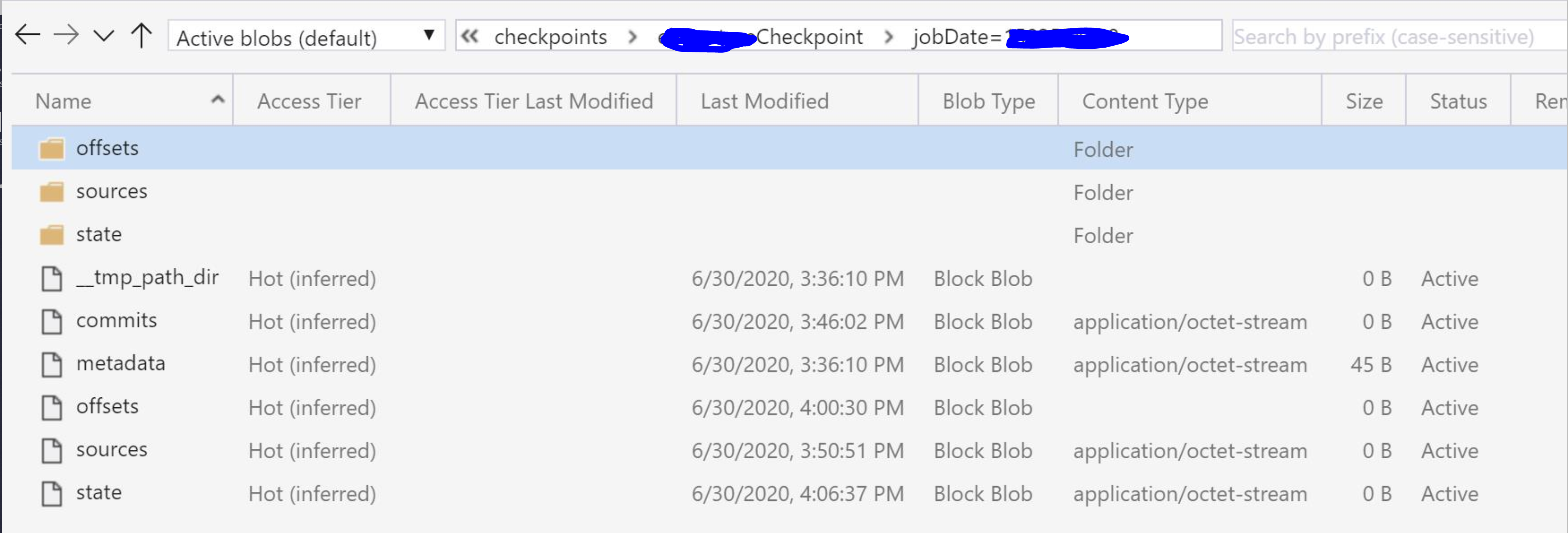
compare with the normal checkpoint:
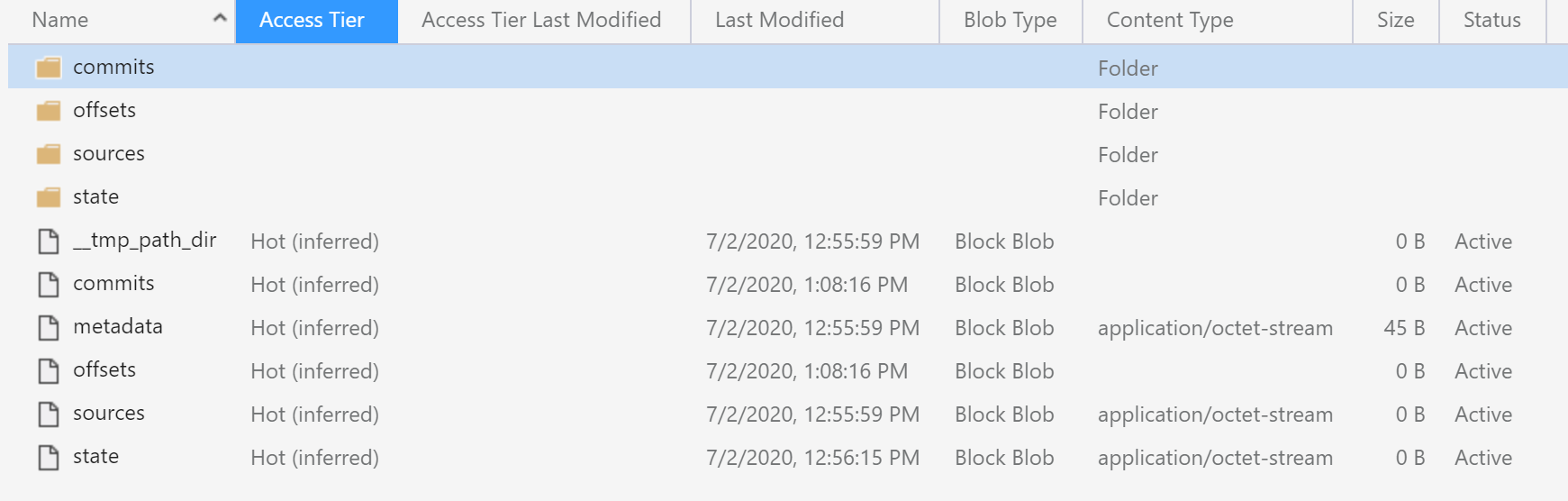
The difference is obvious: there is no commits in the checkpoint path. It means the streaming job didn’t succeed in processing even a single micro-batch.
Possible Causes
It is really tough to debug this issue because no error message shown up and just several misleading warning messages in the executor’s error logs.
Usually, there are several possible reasons to cause streaming processing job stuck, such as:
Total size of state per worker is too large which leads to higher overheads of snapshotting and JVM GC pauses.
Number of shuffle partitions is too high, so the cost of writing state to HDFS will increase which cause the higher latency.
NSG rules added to Databricks Vnet might block some ports and thus infect worker to worker communication.
Databricks mounted blobs are expired and need to rotate the storage connection string and databricks access token.
Databricks cluster version is deprecated and not supported any more.
Spark .metadata directory is messed up. We need to delete the metadata and let the pipeline recreate a new one. but for this one, it would complete micro-batch, and it just do nothing in the process.
But none of them work this time. We struggle to figure out the root cause is:
- Azure blob storage has too many files in the checkpoint folder which slow down the read and write speed.
I compare the DAG visualization with normal job’s, it is shown that the StateStoreSave stage takes much longer (16 hours) than the normal one (21 seconds). StateStoreSave is the stage when spark store current streaming process status in checkpoint. Thus the issue exists in checkpoints. More info for StateStoreSave can be found here
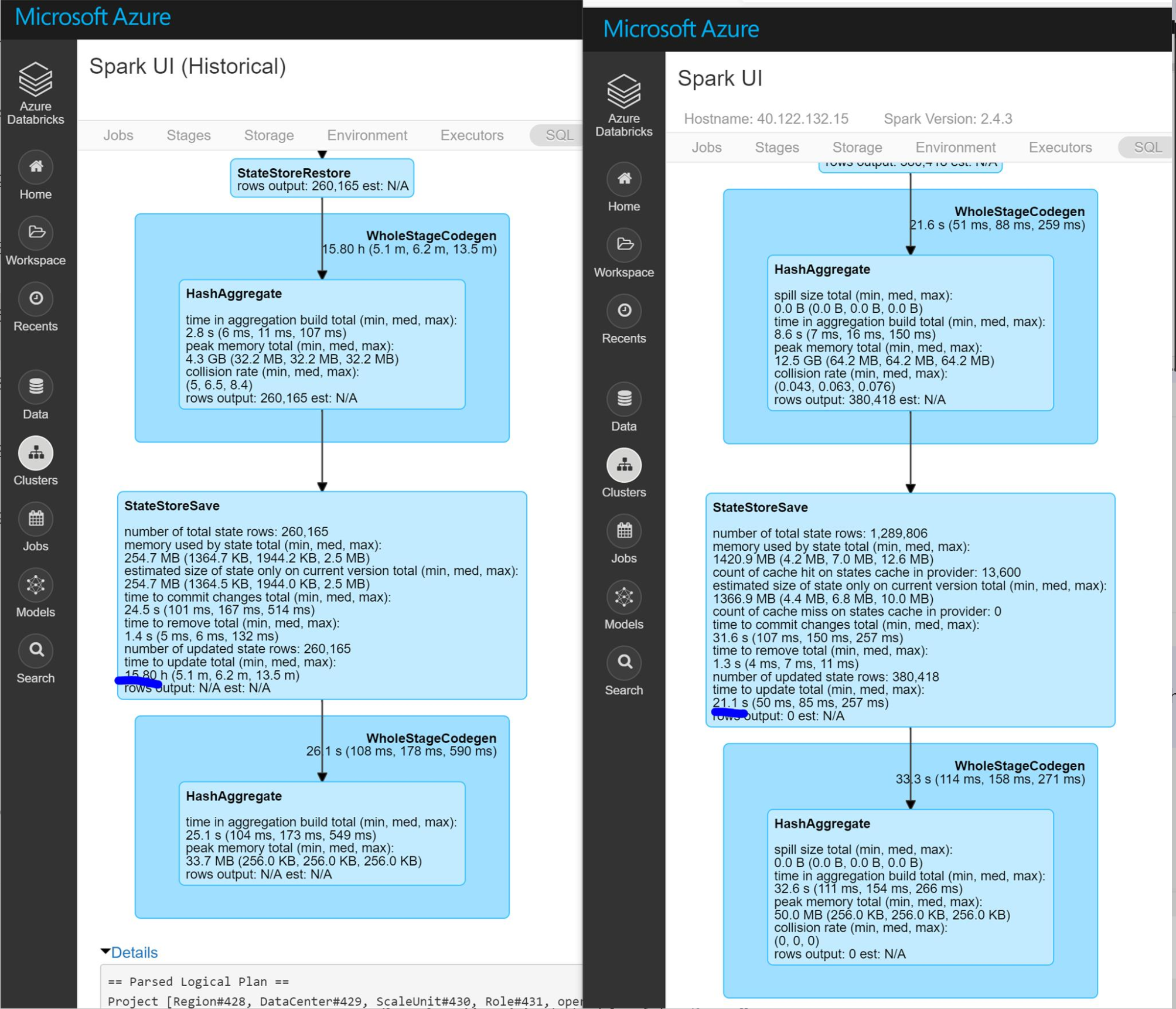
From this detailed stage information, we can get:
number of total state rows is not the concern. we cannot solve the issue by reduce the watermark threshold or recreate checkpoint.
memory used by state total is lower than the normal state. so it is not a JVM GC pause issue.
time to update total is the pain point. It takes longer even the number of updated state rows is less, which point the issue to the write speed in blob storage.
In the checkpoint folder, we stored around 17 million checkpoints for each region. After I delete the whole checkpoint folder and restart the streaming job, the issue is fixed. I am not 100% sure about the reason for it. One possible reason for it is Azure blob storage doesn’t support hierarchical namespace, and it just mimic hierarchical directory structure by using slashes in the name.
Solutions
Solution 1 - migrate Azure blob storage to Azure Data Lake Gen2 which supports hierarchical namespace.
Solution 2 - delete checkpoint folder and decrease retention period.
Step1: Stop current streaming job
Step2: Delete .metadata directory and checkpoint folder
Step3: Add a failover mechanism so that the streaming job will resume from where the streaming job stopped in the last successful data persistence.
Here is my failover mechanism if no checkpoint found, so we can delete the checkpoint folder without losing state.
1 | try: |
Step 4: restart the streaming job.
Step 5: Add retention policy to the checkpoint folder to decrease the checkpoints lifetime.