Deploy Spark .NET app on Databricks
I struggled to deploy a Spark .NET app on Databricks scheduled by Azure Data Factory pipeline. Here are the notes on the solutions how I finally figured out.
From this chapter, you can step-by-step create a Spark .NET app and deploy it either on Databricks directly or scheduled by an Azure Data Factory pipeline.
Prepare a Spark .NET application
This doc teaches you how to run a Spark .NET app using .NET Core. If you are familiar with .NET, we can simplify the process as:
Prepare environment.
1.1 Install the following dependencies: .NET, Java, compression software, Apache Spark, .NET for Apache Spark, WinUtils.
1.2 Set
DOTNET_WORKER_DIRenvironment variable.1.3 Verify you have all dependencies: you are good if you run
dotnet,java,mvn,spark-shellfrom command line successfully.Code a demo app to count words.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34using Microsoft.Spark.Sql;
namespace MySparkApp
{
class Program
{
static void Main(string[] args)
{
// Create a Spark session.
SparkSession spark = SparkSession
.Builder()
.AppName("word_count_sample")
.GetOrCreate();
// Create initial DataFrame.
DataFrame dataFrame = spark.Read().Text("input.txt");
// Count words.
DataFrame words = dataFrame
.Select(Functions.Split(Functions.Col("value"), " ").Alias("words"))
.Select(Functions.Explode(Functions.Col("words"))
.Alias("word"))
.GroupBy("word")
.Count()
.OrderBy(Functions.Col("count").Desc());
// Show results.
words.Show();
// Stop Spark session.
spark.Stop();
}
}
}
Build your app.
1
dotnet build
Locally submit your app to run on Apache Spark.
1
2
3
4
5spark-submit \
--class org.apache.spark.deploy.dotnet.DotnetRunner \
--master local \
microsoft-spark-2.4.x-<version>.jar \
dotnet HelloSpark.dllIf it is successful, you can see the word count data written on the console.
Prepare dependencies on Databricks
Download Microsoft.Spark.Worker which helps Apache Spark execute your app.
Download install-worker.sh which copys .NET for Apache Spark dependencies into your cluster’s nodes.
Download db-init.sh which installs dependencies on your Databricks cluster.
Publish your Spark .NET app.
1
dotnet publish -c Release -f netcoreapp3.1 -r ubuntu.16.04-x64
Compress the published app files in the previous step. Navigate to mySparkApp/bin/Release/netcoreapp3.1/ubuntu.16.04-x64, compress
Publishfolder as a zip file.Upload files to DBFS.
1
2
3
4
5
6
7
8
9
10databricks fs cp db-init.sh dbfs:/spark-dotnet/db-init.sh
databricks fs cp install-worker.sh dbfs:/spark-dotnet/install-worker.sh
databricks fs cp Microsoft.Spark.Worker.netcoreapp3.1.linux-x64-0.6.0.tar.gz dbfs:/spark-dotnet/ Microsoft.Spark.Worker.netcoreapp2.1.linux-x64-0.6.0.tar.gz
cd mySparkApp
databricks fs cp input.txt dbfs:/input.txt
cd mySparkApp\bin\Release\netcoreapp3.1\ubuntu.16.04-x64 directory
databricks fs cp mySparkApp.zip dbfs:/spark-dotnet/publish.zip
databricks fs cp microsoft-spark-2.4.x-0.6.0.jar dbfs:/spark-dotnet/microsoft-spark-2.4.x-0.6.0.jar
- Then all the dependencies are ready. We can deploy it on Databricks.
How to deploy
We can run .NET for Apache Spark apps on Databricks, but it is not what we usually do for Python or Scala jobs. For the Python or Scala jobs, we can just start a Notebook task for them. But for Spark .NET job, we need to use the “spark-submit” or “Jar” tasks.
Scheduled by Azure Data Factory pipeline
Deploy using Set Jar
Generate a Databricks access token for Azure Data Factory to access.
1.1 In Databricks workspace, select your user profile in the upper right, and select User Settings.
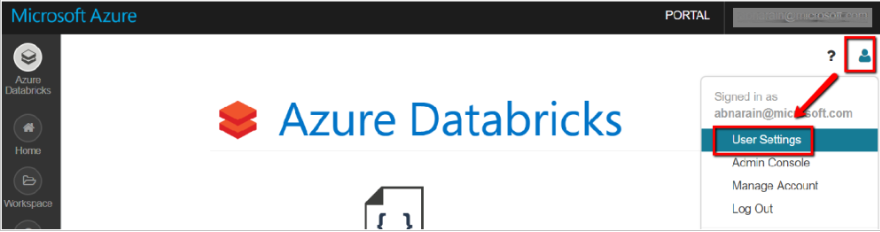
1.2 Select Generate New Token under the Access Tokens tab.
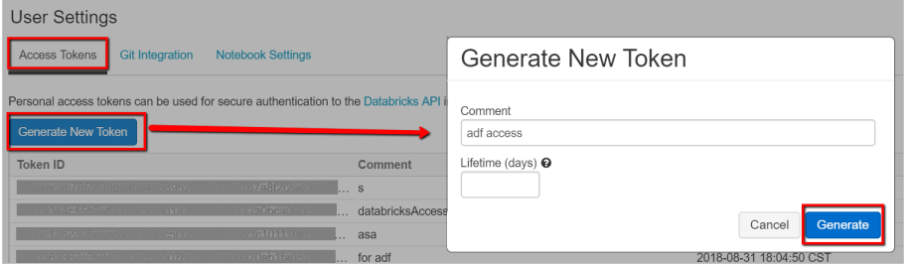
1.3 Save the access token for later use in creating a Databricks linked service. Usually save it in Azure Key Vault for security.
Navigated to the Pipelines page on Azure Data Factory, create a new pipeline, search for Databricks activities, drag the Jar task to panel.
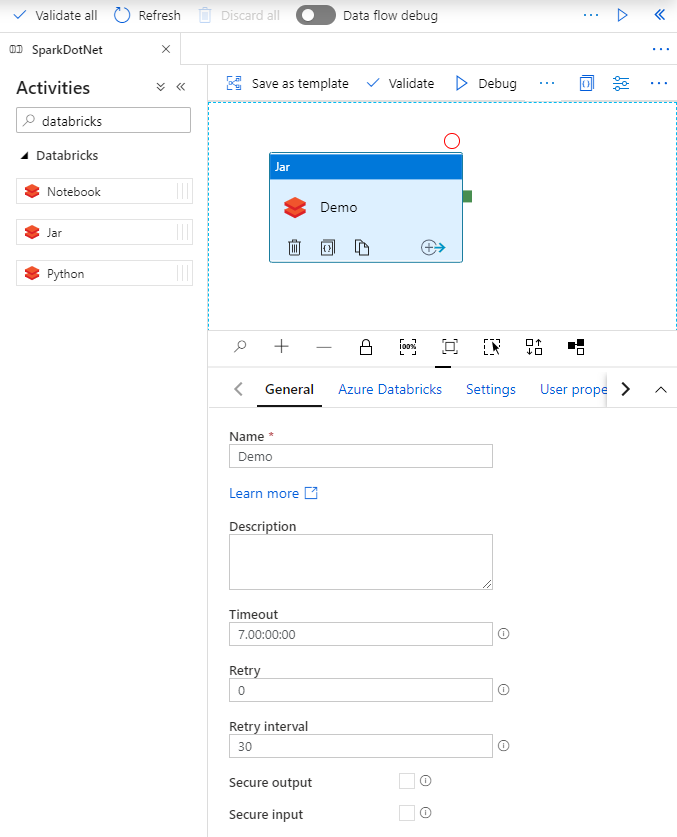
In the Jar activity Demo, updates the paths and settings as needed. Databricks linked service should be created using access token generated on Databricks previously. Remember to add init script for cluster settings.
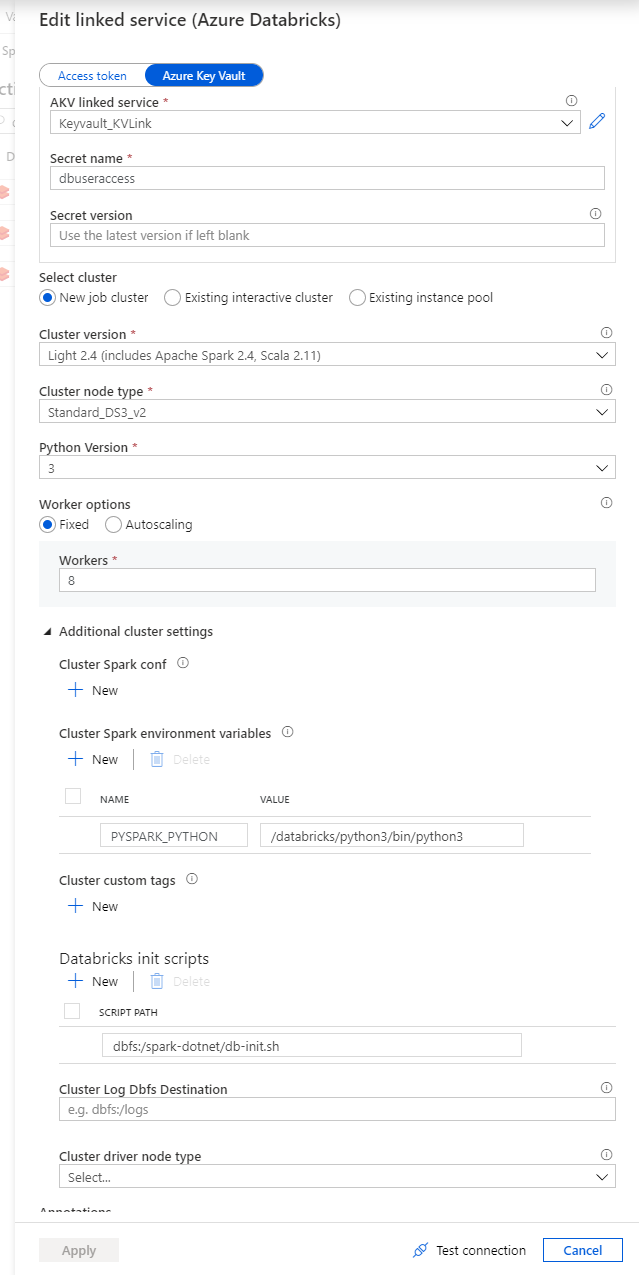
Check the Jar settings. Main class name is org.apache.spark.deploy.dotnet.DotnetRunner. Parameters will pass to the main class. it must have your app publish.zip and your app name as the first two parameters. The rest parameters are what your app need. Append libraries are microsoft-spark-2.4.x-0.10.0.jar on dbfs.
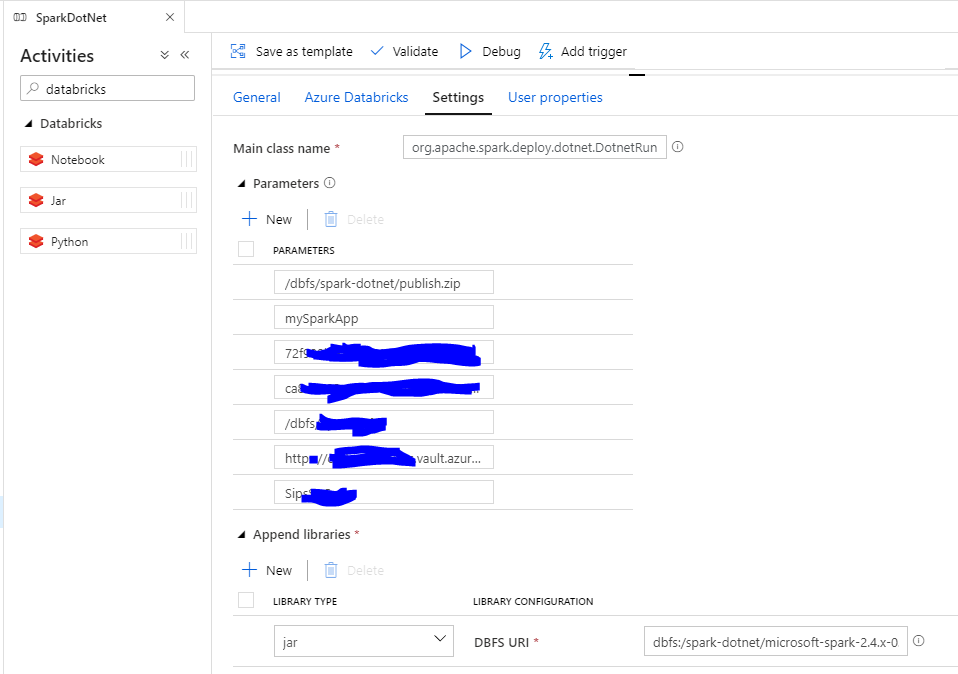
Click Debug to run a test for the current pipeline.
Save the newly added pipeline by click Publish all.
Directly on databricks
1. Deploy using Spark-submit
Navigate to Databricks Workspace and create a job. Select Task as spark-submit. Set job parameters。
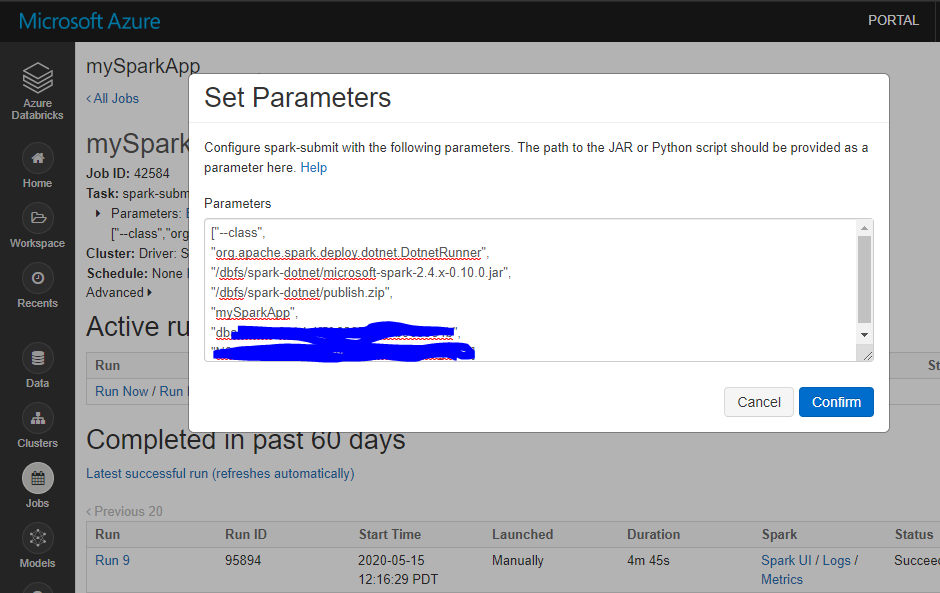
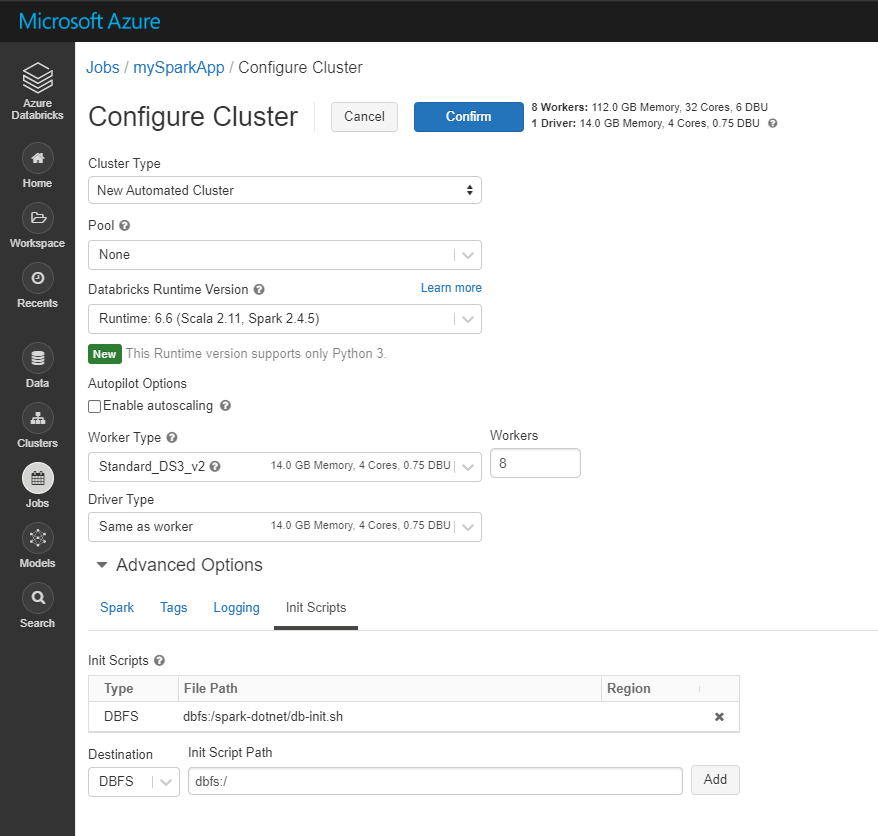
When configure Cluster, need to add init script located on DBFS (Databricks Filesystem).
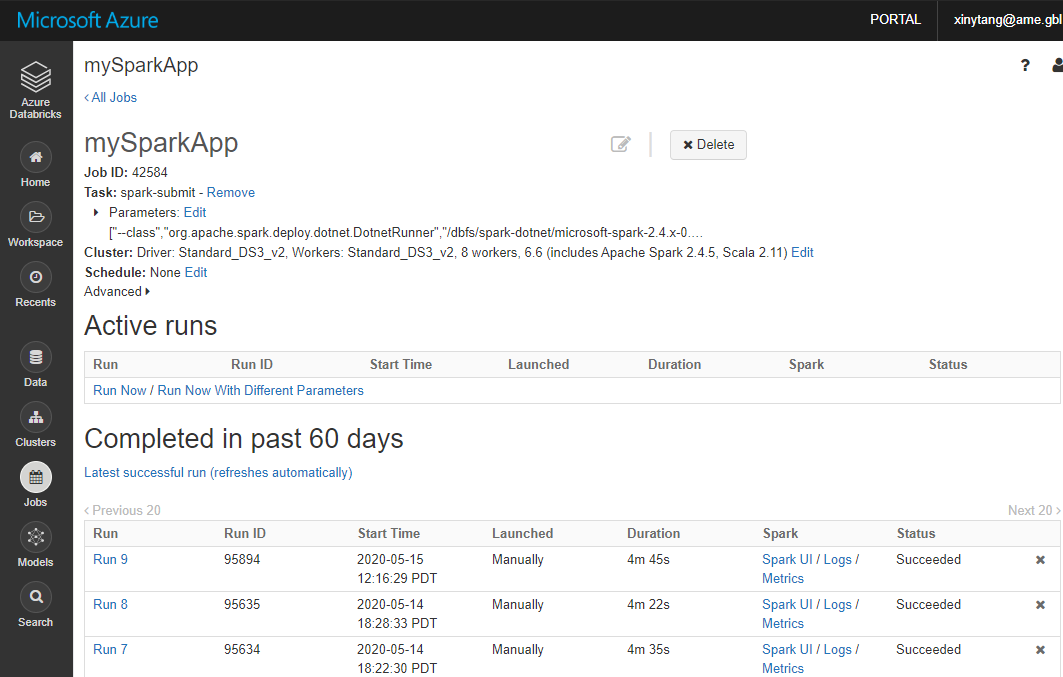
select Run Now to test the job. Once the job’s cluster is created, your Spark job will be submitted.
2. Deploy using Set Jar
We can also use the Jar task to deploy on Databricks. The settings should be the same with the one triggered by Azure Data Factory.
Reference
https://docs.microsoft.com/en-us/dotnet/spark/how-to-guides/databricks-deploy-methods
https://docs.microsoft.com/en-us/azure/data-factory/solution-template-databricks-notebook
https://docs.microsoft.com/en-us/azure/data-factory/transform-data-databricks-jar
https://docs.microsoft.com/en-us/dotnet/spark/tutorials/get-started
https://dotnet.microsoft.com/learn/data/spark-tutorial/intro